Contents
- 1 Ж░юВџћ
- 2 вДѕВЋёВйћьћё Ж│╝ВаЋ(markov process)
- 3 вДѕВЋёВйћьћё вХёВёЮВЮў ВаёВаю
- 4 ВўѕВаю1: ВІаЖиюВёюв▓ё Вўцьћѕ
- 5 ВўѕВаю2: ВЮ╝ВІюВЃЂьЃю, ВъгЖиђВЃЂьЃю, ьЮАВѕўВЃЂьЃю
- 6 ВўѕВаю3: ВбЁьЋЕв│ЉВЏљ ВІгВъЦ В╣ўвБї в│ЉвЈЎ
- 7 ВўѕВаю4: ВбЁьЋЕв│ЉВЏљ ВІгВъЦ В╣ўвБї в│ЉвЈЎ - markovchain packages
- 8 ВўѕВаю5: вЇ░ВЮ┤ьё░ ьћёваѕВъёВЮё ВаёВЮ┤ ьЎЋвЦавАю вДївЊцЖИ░
- 9 ВўѕВаю6: ьЮАВѕўВЃЂьЃюЖ░ђ ьЈгьЋевљю ВаёВЮ┤ьќЅваг
- 10 HMM(Hidden Markov Model)
- 11 msm package
- 12 ВаЋвДљ ВЮ┤вЪ░ в│хВъАьЋюЖ▓ї ьЋёВџћьЋюЖ░ђ?
- 13 В░ИЖ│аВъљвБї
[edit]
1 Ж░юВџћ #
- вДѕВЋёВйћьћё вХёВёЮВЮђ ьЎЋвЦаВаЂВЮИ ЖИ░в▓ЋВю╝вАю Ж▓░ВаЋ ВЃЂьЎЕВЌљ вїђьЋю ьЎЋвЦаВаЂ ВаЋв│┤вДї ВаюЖ│хьЋювІц. ВдЅ, ВёюВѕаВаЂВъё
- Вќ┤вќц ВІюВіцьЁюВЮў ьўёВъг ВЃЂьЃювЦ╝ вХёВёЮьЋўВЌг ЖиИ ВІюВіцьЁюВЮў в»ИвъўВЮў ВЃЂьЃювЦ╝ ВўѕВИАьЋе.
- ВІюЖ░ёВЮў ьЮљвдёВЌљ вћ░вЦИ ВЃЂьЃю в│ђьЎћЖ░ђ ьЎЋвЦаВаЂВю╝вАю ВЏђВДЂВЮ╝ вЋїВЌљ ВѓгВџЕьЋе.
- вИївъювЊювфЁ ЖхљВ▓┤, ВЮИЖхгВЮ┤вЈЎ, ВЮИВѓг вЊ▒
[edit]
2 вДѕВЋёВйћьћё Ж│╝ВаЋ(markov process) #
- ВЃЂьЃю S1ВЌљВёю ВЃЂьЃю S2вАю в│ђьЎћьЋа вЋї ьЎЋвЦаВЮ┤ ВаЂВџЕвљўвіћ Ж│╝ВаЋВЮё 'ьЎЋвЦаВаЂ Ж░ђВаЋ(stochastic process)'вЮ╝Ж│а ьЋе.
- ВЃЂьЃю S1ВЌљВёю ВЃЂьЃю S2вАю в│ђьЎћьЋа вЋї S2Ж░ђ S1ВЌљ ВЮўьЋ┤ Ж▓░ВаЋвљўвіћ ьЎЋвЦаВаЂ Ж░ђВаЋВЮђ 'вДѕВЋёВйћьћё Ж│╝ВаЋ(markov process)'вЮ╝Ж│а ьЋе.
- ВЃЂьЃю S1ВЌљВёю ВЃЂьЃю S2вАю в│ђьЎћьЋа вЋїВЮў ВаёВЮ┤ ьЎЋвЦа(transition probablility)ВЮ┤ ВІюЖ░ёВЮ┤ ВДђвѓгВЮїВЌљвЈё в│ђьЎћьЋўВДђ ВЋіВю╝вЕ┤ 'вДѕВЋёВйћьћё В▓┤ВЮИ(markov chain)'ВЮ┤вЮ╝Ж│а ьЋе.
- ВІюЖ░ёВЮ┤ Ж▓йЖ│╝ьЋ┤вЈё ВЃЂьЃю ьЎЋвЦаВЌљ в│ђьЎћЖ░ђ ВЌєВю╝вЕ┤ 'ВЋѕВаЋВЃЂьЃю(steady-state, long-run, equilibrium probablilty)' вЮ╝Ж│а ьЋе.
- В▒ЁВЌљвіћ ВЋѕВаЋ ВЃЂьЃювЦ╝ Ж│ёВѓ░ьЋўвацЖ│а ВЌ░вдйв░ЕВаЋВІЮ ьњђЖ│а ЖиИвЪгвіћвЇ░, ЖиИваЄЖ▓ї ВЋѕьЋ┤вЈё ЖиИвЃЦ 100вІеЖ│ё, 1000вІеЖ│ёвАю вЈївдгвЕ┤ ьЎЋВЮИьЋа Вѕў ВъѕвІц.
- В▒ЁВЌљвіћ ВЋѕВаЋ ВЃЂьЃювЦ╝ Ж│ёВѓ░ьЋўвацЖ│а ВЌ░вдйв░ЕВаЋВІЮ ьњђЖ│а ЖиИвЪгвіћвЇ░, ЖиИваЄЖ▓ї ВЋѕьЋ┤вЈё ЖиИвЃЦ 100вІеЖ│ё, 1000вІеЖ│ёвАю вЈївдгвЕ┤ ьЎЋВЮИьЋа Вѕў ВъѕвІц.
[edit]
3 вДѕВЋёВйћьћё вХёВёЮВЮў ВаёВаю #
- ВІюВіцьЁюВЮђ ВюаьЋюьЋю ВѕўВЮў ВЃЂьЃювЦ╝ Ж░ђВДёвІц.
- ВІюВіцьЁюВЮђ ВЌгвЪг ЖИ░Ж░ё вЈЎВЋѕ ВА┤ВъгьЋювІц.
- Ж░Ђ ЖИ░Ж░ёВЌљ ВъѕВќ┤ ВІюВіцьЁюВЮђ ьЋю ВЃЂьЃюВЌљ ВєЇьЋювІц.
- Ж░Ђ ВЃЂьЃювіћ ВЃЂьўИв░░ьЃђВаЂВЮ┤вІц.
- ВаёВЮ┤ ьЎЋвЦаВЮђ ВІюЖ░ёВЮ┤ Ж▓йЖ│╝ьЋ┤вЈё ВЮ╝ВаЋьЋўвІц.
- ьі╣ВаЋ ЖИ░Ж░ёВЮў ВЃЂьЃювіћ в░ћвАю ВаёВЮў ВЃЂьЃюВЎђ ВаёВЮ┤ьЎЋвЦаВЌљ ВЮўВА┤ьЋювІц.
- ВЃЂьЃюв│ђьЎћвіћ Ж░Ђ ЖИ░Ж░ёВЌљ ьЋю в▓ѕвДї в░юВЃЮьЋювІц.
- Ж░Ђ ЖИ░Ж░ёВЮђ ЖИИВЮ┤Ж░ђ ВЮ╝ВаЋьЋўвІц.
- вДѕВЋёВйћьћё вХёВёЮВЮђ ьўёВъгВЮў ВІюВ┤ѕ ВЃЂьЎЕВЌљВёю ВІюВъЉьЋювІц.
[edit]
4 ВўѕВаю1: ВІаЖиюВёюв▓ё Вўцьћѕ #
- BВёюв▓ё(Ж▓їВъё)вЦ╝ ВЃѕвАю ВўцьћѕьќѕвІц. ВЮ┤ВаёВЌљ ВІаЖию Вёюв▓ё ВўцьћѕВІюВЮў ВЮ╝вІеВюёВЮў Ж│аЖ░ЮВЮў ВЮ┤вЈЎВЌљ вїђьЋю ВаёВЮ┤ ьЎЋвЦаВЮё ВА░ВѓгьЋ┤в┤цвЇћвІѕ вІцВЮїЖ│╝ Ж░ЎвЇћвЮ╝.
- ЖхгВёюв▓ё -> ЖхгВёюв▓ё: 0.9
- ЖхгВёюв▓ё -> ВІаВёюв▓ё: 0.1
- ВІаВёюв▓ё -> ЖхгВёюв▓ё: 0.3
- ЖхгВёюв▓ё -> ЖхгВёюв▓ё: 0.7
- ЖхгВёюв▓ё -> ЖхгВёюв▓ё: 0.9
- В▓ўВЮїВЌљ AВёюв▓ёВЌљВёю 100вфЁВЮ┤ ВЮ┤ВџЕьЋўЖ│а ВъѕВЌѕвІц. (ВЮ╝вІеВЮђ Ж│еВ╣ў ВЋёьћёвІѕ ВІаЖиюЖ░ђВъЁВЮђ ВЌєвІцЖ│а Ж░ђВаЋьЋўВъљ)
- 22ВЮ╝В░е ВаЋвЈёвЕ┤ ВЋѕВаЋВЃЂьЃюЖ░ђ вљўЖ│а, ЖхгВёюв▓ёВЌљвіћ 75вфЁ, ВІаВёюв▓ёВЌљвіћ 25вфЁВЮ┤ вљювІцЖ│а ВўѕВИАьЋа Вѕў ВъѕвІц.
x1 <- c(0.9, 0.1)
x2 <- c(0.3, 0.7)
tp <- rbind(x1, x2) #ВаёВЮ┤ьЎЋвЦа
ss <- rbind(c(100,0)) #ВІюВ┤ѕ
for(t in seq(1:30)){
prev_tp <- ss%*%tp
out <- paste(t, "ВЮ╝В░е: ", "ЖхгВёюв▓ё:", round(prev_tp[1,1], 3), "ВІаВёюв▓ё:", round(prev_tp[1,2], 3))
ss <- prev_tp
print (out)
}
Ж▓░Ж│╝
[1] "1 ВЮ╝В░е: ЖхгВёюв▓ё: 90 ВІаВёюв▓ё: 10" [1] "2 ВЮ╝В░е: ЖхгВёюв▓ё: 84 ВІаВёюв▓ё: 16" [1] "3 ВЮ╝В░е: ЖхгВёюв▓ё: 80.4 ВІаВёюв▓ё: 19.6" [1] "4 ВЮ╝В░е: ЖхгВёюв▓ё: 78.24 ВІаВёюв▓ё: 21.76" [1] "5 ВЮ╝В░е: ЖхгВёюв▓ё: 76.944 ВІаВёюв▓ё: 23.056" [1] "6 ВЮ╝В░е: ЖхгВёюв▓ё: 76.166 ВІаВёюв▓ё: 23.834" [1] "7 ВЮ╝В░е: ЖхгВёюв▓ё: 75.7 ВІаВёюв▓ё: 24.3" [1] "8 ВЮ╝В░е: ЖхгВёюв▓ё: 75.42 ВІаВёюв▓ё: 24.58" [1] "9 ВЮ╝В░е: ЖхгВёюв▓ё: 75.252 ВІаВёюв▓ё: 24.748" [1] "10 ВЮ╝В░е: ЖхгВёюв▓ё: 75.151 ВІаВёюв▓ё: 24.849" [1] "11 ВЮ╝В░е: ЖхгВёюв▓ё: 75.091 ВІаВёюв▓ё: 24.909" [1] "12 ВЮ╝В░е: ЖхгВёюв▓ё: 75.054 ВІаВёюв▓ё: 24.946" [1] "13 ВЮ╝В░е: ЖхгВёюв▓ё: 75.033 ВІаВёюв▓ё: 24.967" [1] "14 ВЮ╝В░е: ЖхгВёюв▓ё: 75.02 ВІаВёюв▓ё: 24.98" [1] "15 ВЮ╝В░е: ЖхгВёюв▓ё: 75.012 ВІаВёюв▓ё: 24.988" [1] "16 ВЮ╝В░е: ЖхгВёюв▓ё: 75.007 ВІаВёюв▓ё: 24.993" [1] "17 ВЮ╝В░е: ЖхгВёюв▓ё: 75.004 ВІаВёюв▓ё: 24.996" [1] "18 ВЮ╝В░е: ЖхгВёюв▓ё: 75.003 ВІаВёюв▓ё: 24.997" [1] "19 ВЮ╝В░е: ЖхгВёюв▓ё: 75.002 ВІаВёюв▓ё: 24.998" [1] "20 ВЮ╝В░е: ЖхгВёюв▓ё: 75.001 ВІаВёюв▓ё: 24.999" [1] "21 ВЮ╝В░е: ЖхгВёюв▓ё: 75.001 ВІаВёюв▓ё: 24.999" [1] "22 ВЮ╝В░е: ЖхгВёюв▓ё: 75 ВІаВёюв▓ё: 25" [1] "23 ВЮ╝В░е: ЖхгВёюв▓ё: 75 ВІаВёюв▓ё: 25" [1] "24 ВЮ╝В░е: ЖхгВёюв▓ё: 75 ВІаВёюв▓ё: 25" [1] "25 ВЮ╝В░е: ЖхгВёюв▓ё: 75 ВІаВёюв▓ё: 25" [1] "26 ВЮ╝В░е: ЖхгВёюв▓ё: 75 ВІаВёюв▓ё: 25" [1] "27 ВЮ╝В░е: ЖхгВёюв▓ё: 75 ВІаВёюв▓ё: 25" [1] "28 ВЮ╝В░е: ЖхгВёюв▓ё: 75 ВІаВёюв▓ё: 25" [1] "29 ВЮ╝В░е: ЖхгВёюв▓ё: 75 ВІаВёюв▓ё: 25" [1] "30 ВЮ╝В░е: ЖхгВёюв▓ё: 75 ВІаВёюв▓ё: 25"
[edit]
5 ВўѕВаю2: ВЮ╝ВІюВЃЂьЃю, ВъгЖиђВЃЂьЃю, ьЮАВѕўВЃЂьЃю #
вДїВЋй ВўѕВаю1ВЌљВёю ВІаВёюв▓ёВЌљВёю ЖхгВёюв▓ёвАю ВЮ┤вЈЎВЮ┤ ВЌєвІцЖ│а Ж░ђВаЋьЋўвЕ┤, 116ВЮ╝В░еВЌљ ВЋѕВаЋВЃЂьЃюВЌљ вЈїВъЁьЋювІц. ВдЅ, ЖхгВёюв▓ёВЌљ ВѓгвъїВЮ┤ ьЋювфЁвЈё вѓеВДђ ВЋіЖ▓ї вљювІцЖ│а ВўѕВИА ьЋа Вѕў ВъѕвІц. ВЮ┤вЪ░ ВЃЂьЃювЦ╝ 'ВЮ╝ВІю ВЃЂьЃю(transient state)'вЮ╝Ж│а ьЋювІц. ВЮ╝ВІю ВЃЂьЃюЖ░ђ ВЋёвІї ВўѕВаю1Ж│╝ Ж░ЎВЮђ ВЃЂьЃювЦ╝ 'ВъгЖиђ ВЃЂьЃю(recurrent state)'вЮ╝Ж│а ьЋўвЕ░, ВъгЖиђ ВЃЂьЃю ВцЉ ВЋѕВаЋ ВЃЂьЃювЦ╝ 'ьЮАВѕў ВЃЂьЃю(absorbing state)'вЮ╝Ж│а ьЋювІц. ьЮАВѕў ВЃЂьЃювіћ ВІюВіцьЁюВЮ┤ ЖХЂЖи╣ВаЂВю╝вАю вЈёвІгьЋўвіћ ВЃЂьЃюВЮ┤в»ђвАю ьўёВІцВаЂВю╝вАю ВцЉВџћьЋю ВЮўв»ИвЦ╝ Ж░ќвіћ Ж▓йВџ░Ж░ђ вДјвІц. (вЮ╝Ж│а ![[http]](/moniwiki/imgs/http.png) ВЌгЖИ░ВЌљВёю ЖиИвЪгвЇћвЮ╝)
ВЌгЖИ░ВЌљВёю ЖиИвЪгвЇћвЮ╝)
ВЌгЖИ░ВЌљВёю ЖиИвЪгвЇћвЮ╝)
x1 <- c(0.9, 0.1)
x2 <- c(0.0, 1.0)
tp <- rbind(x1, x2) #ВаёВЮ┤ьЎЋвЦа
ss <- rbind(c(100,0)) #ВІюВ┤ѕ
for(t in seq(1:120)){
prev_tp <- ss%*%tp
out <- paste(t, "ВЮ╝В░е: ", "ЖхгВёюв▓ё:", round(prev_tp[1,1], 3), "ВІаВёюв▓ё:", round(prev_tp[1,2], 3))
ss <- prev_tp
print (out)
}
[1] "1 ВЮ╝В░е: ЖхгВёюв▓ё: 90 ВІаВёюв▓ё: 10"
[1] "2 ВЮ╝В░е: ЖхгВёюв▓ё: 81 ВІаВёюв▓ё: 19"
[1] "3 ВЮ╝В░е: ЖхгВёюв▓ё: 72.9 ВІаВёюв▓ё: 27.1"
[1] "4 ВЮ╝В░е: ЖхгВёюв▓ё: 65.61 ВІаВёюв▓ё: 34.39"
[1] "5 ВЮ╝В░е: ЖхгВёюв▓ё: 59.049 ВІаВёюв▓ё: 40.951"
[1] "6 ВЮ╝В░е: ЖхгВёюв▓ё: 53.144 ВІаВёюв▓ё: 46.856"
[1] "7 ВЮ╝В░е: ЖхгВёюв▓ё: 47.83 ВІаВёюв▓ё: 52.17"
[1] "8 ВЮ╝В░е: ЖхгВёюв▓ё: 43.047 ВІаВёюв▓ё: 56.953"
[1] "9 ВЮ╝В░е: ЖхгВёюв▓ё: 38.742 ВІаВёюв▓ё: 61.258"
[1] "10 ВЮ╝В░е: ЖхгВёюв▓ё: 34.868 ВІаВёюв▓ё: 65.132"
[1] "11 ВЮ╝В░е: ЖхгВёюв▓ё: 31.381 ВІаВёюв▓ё: 68.619"
[1] "12 ВЮ╝В░е: ЖхгВёюв▓ё: 28.243 ВІаВёюв▓ё: 71.757"
[1] "13 ВЮ╝В░е: ЖхгВёюв▓ё: 25.419 ВІаВёюв▓ё: 74.581"
[1] "14 ВЮ╝В░е: ЖхгВёюв▓ё: 22.877 ВІаВёюв▓ё: 77.123"
[1] "15 ВЮ╝В░е: ЖхгВёюв▓ё: 20.589 ВІаВёюв▓ё: 79.411"
[1] "16 ВЮ╝В░е: ЖхгВёюв▓ё: 18.53 ВІаВёюв▓ё: 81.47"
[1] "17 ВЮ╝В░е: ЖхгВёюв▓ё: 16.677 ВІаВёюв▓ё: 83.323"
[1] "18 ВЮ╝В░е: ЖхгВёюв▓ё: 15.009 ВІаВёюв▓ё: 84.991"
[1] "19 ВЮ╝В░е: ЖхгВёюв▓ё: 13.509 ВІаВёюв▓ё: 86.491"
[1] "20 ВЮ╝В░е: ЖхгВёюв▓ё: 12.158 ВІаВёюв▓ё: 87.842"
[1] "21 ВЮ╝В░е: ЖхгВёюв▓ё: 10.942 ВІаВёюв▓ё: 89.058"
[1] "22 ВЮ╝В░е: ЖхгВёюв▓ё: 9.848 ВІаВёюв▓ё: 90.152"
[1] "23 ВЮ╝В░е: ЖхгВёюв▓ё: 8.863 ВІаВёюв▓ё: 91.137"
[1] "24 ВЮ╝В░е: ЖхгВёюв▓ё: 7.977 ВІаВёюв▓ё: 92.023"
[1] "25 ВЮ╝В░е: ЖхгВёюв▓ё: 7.179 ВІаВёюв▓ё: 92.821"
[1] "26 ВЮ╝В░е: ЖхгВёюв▓ё: 6.461 ВІаВёюв▓ё: 93.539"
[1] "27 ВЮ╝В░е: ЖхгВёюв▓ё: 5.815 ВІаВёюв▓ё: 94.185"
[1] "28 ВЮ╝В░е: ЖхгВёюв▓ё: 5.233 ВІаВёюв▓ё: 94.767"
[1] "29 ВЮ╝В░е: ЖхгВёюв▓ё: 4.71 ВІаВёюв▓ё: 95.29"
[1] "30 ВЮ╝В░е: ЖхгВёюв▓ё: 4.239 ВІаВёюв▓ё: 95.761"
[1] "31 ВЮ╝В░е: ЖхгВёюв▓ё: 3.815 ВІаВёюв▓ё: 96.185"
[1] "32 ВЮ╝В░е: ЖхгВёюв▓ё: 3.434 ВІаВёюв▓ё: 96.566"
[1] "33 ВЮ╝В░е: ЖхгВёюв▓ё: 3.09 ВІаВёюв▓ё: 96.91"
[1] "34 ВЮ╝В░е: ЖхгВёюв▓ё: 2.781 ВІаВёюв▓ё: 97.219"
[1] "35 ВЮ╝В░е: ЖхгВёюв▓ё: 2.503 ВІаВёюв▓ё: 97.497"
[1] "36 ВЮ╝В░е: ЖхгВёюв▓ё: 2.253 ВІаВёюв▓ё: 97.747"
[1] "37 ВЮ╝В░е: ЖхгВёюв▓ё: 2.028 ВІаВёюв▓ё: 97.972"
[1] "38 ВЮ╝В░е: ЖхгВёюв▓ё: 1.825 ВІаВёюв▓ё: 98.175"
[1] "39 ВЮ╝В░е: ЖхгВёюв▓ё: 1.642 ВІаВёюв▓ё: 98.358"
[1] "40 ВЮ╝В░е: ЖхгВёюв▓ё: 1.478 ВІаВёюв▓ё: 98.522"
[1] "41 ВЮ╝В░е: ЖхгВёюв▓ё: 1.33 ВІаВёюв▓ё: 98.67"
[1] "42 ВЮ╝В░е: ЖхгВёюв▓ё: 1.197 ВІаВёюв▓ё: 98.803"
[1] "43 ВЮ╝В░е: ЖхгВёюв▓ё: 1.078 ВІаВёюв▓ё: 98.922"
[1] "44 ВЮ╝В░е: ЖхгВёюв▓ё: 0.97 ВІаВёюв▓ё: 99.03"
[1] "45 ВЮ╝В░е: ЖхгВёюв▓ё: 0.873 ВІаВёюв▓ё: 99.127"
[1] "46 ВЮ╝В░е: ЖхгВёюв▓ё: 0.786 ВІаВёюв▓ё: 99.214"
[1] "47 ВЮ╝В░е: ЖхгВёюв▓ё: 0.707 ВІаВёюв▓ё: 99.293"
[1] "48 ВЮ╝В░е: ЖхгВёюв▓ё: 0.636 ВІаВёюв▓ё: 99.364"
[1] "49 ВЮ╝В░е: ЖхгВёюв▓ё: 0.573 ВІаВёюв▓ё: 99.427"
[1] "50 ВЮ╝В░е: ЖхгВёюв▓ё: 0.515 ВІаВёюв▓ё: 99.485"
[1] "51 ВЮ╝В░е: ЖхгВёюв▓ё: 0.464 ВІаВёюв▓ё: 99.536"
[1] "52 ВЮ╝В░е: ЖхгВёюв▓ё: 0.417 ВІаВёюв▓ё: 99.583"
[1] "53 ВЮ╝В░е: ЖхгВёюв▓ё: 0.376 ВІаВёюв▓ё: 99.624"
[1] "54 ВЮ╝В░е: ЖхгВёюв▓ё: 0.338 ВІаВёюв▓ё: 99.662"
[1] "55 ВЮ╝В░е: ЖхгВёюв▓ё: 0.304 ВІаВёюв▓ё: 99.696"
[1] "56 ВЮ╝В░е: ЖхгВёюв▓ё: 0.274 ВІаВёюв▓ё: 99.726"
[1] "57 ВЮ╝В░е: ЖхгВёюв▓ё: 0.247 ВІаВёюв▓ё: 99.753"
[1] "58 ВЮ╝В░е: ЖхгВёюв▓ё: 0.222 ВІаВёюв▓ё: 99.778"
[1] "59 ВЮ╝В░е: ЖхгВёюв▓ё: 0.2 ВІаВёюв▓ё: 99.8"
[1] "60 ВЮ╝В░е: ЖхгВёюв▓ё: 0.18 ВІаВёюв▓ё: 99.82"
[1] "61 ВЮ╝В░е: ЖхгВёюв▓ё: 0.162 ВІаВёюв▓ё: 99.838"
[1] "62 ВЮ╝В░е: ЖхгВёюв▓ё: 0.146 ВІаВёюв▓ё: 99.854"
[1] "63 ВЮ╝В░е: ЖхгВёюв▓ё: 0.131 ВІаВёюв▓ё: 99.869"
[1] "64 ВЮ╝В░е: ЖхгВёюв▓ё: 0.118 ВІаВёюв▓ё: 99.882"
[1] "65 ВЮ╝В░е: ЖхгВёюв▓ё: 0.106 ВІаВёюв▓ё: 99.894"
[1] "66 ВЮ╝В░е: ЖхгВёюв▓ё: 0.096 ВІаВёюв▓ё: 99.904"
[1] "67 ВЮ╝В░е: ЖхгВёюв▓ё: 0.086 ВІаВёюв▓ё: 99.914"
[1] "68 ВЮ╝В░е: ЖхгВёюв▓ё: 0.077 ВІаВёюв▓ё: 99.923"
[1] "69 ВЮ╝В░е: ЖхгВёюв▓ё: 0.07 ВІаВёюв▓ё: 99.93"
[1] "70 ВЮ╝В░е: ЖхгВёюв▓ё: 0.063 ВІаВёюв▓ё: 99.937"
[1] "71 ВЮ╝В░е: ЖхгВёюв▓ё: 0.056 ВІаВёюв▓ё: 99.944"
[1] "72 ВЮ╝В░е: ЖхгВёюв▓ё: 0.051 ВІаВёюв▓ё: 99.949"
[1] "73 ВЮ╝В░е: ЖхгВёюв▓ё: 0.046 ВІаВёюв▓ё: 99.954"
[1] "74 ВЮ╝В░е: ЖхгВёюв▓ё: 0.041 ВІаВёюв▓ё: 99.959"
[1] "75 ВЮ╝В░е: ЖхгВёюв▓ё: 0.037 ВІаВёюв▓ё: 99.963"
[1] "76 ВЮ╝В░е: ЖхгВёюв▓ё: 0.033 ВІаВёюв▓ё: 99.967"
[1] "77 ВЮ╝В░е: ЖхгВёюв▓ё: 0.03 ВІаВёюв▓ё: 99.97"
[1] "78 ВЮ╝В░е: ЖхгВёюв▓ё: 0.027 ВІаВёюв▓ё: 99.973"
[1] "79 ВЮ╝В░е: ЖхгВёюв▓ё: 0.024 ВІаВёюв▓ё: 99.976"
[1] "80 ВЮ╝В░е: ЖхгВёюв▓ё: 0.022 ВІаВёюв▓ё: 99.978"
[1] "81 ВЮ╝В░е: ЖхгВёюв▓ё: 0.02 ВІаВёюв▓ё: 99.98"
[1] "82 ВЮ╝В░е: ЖхгВёюв▓ё: 0.018 ВІаВёюв▓ё: 99.982"
[1] "83 ВЮ╝В░е: ЖхгВёюв▓ё: 0.016 ВІаВёюв▓ё: 99.984"
[1] "84 ВЮ╝В░е: ЖхгВёюв▓ё: 0.014 ВІаВёюв▓ё: 99.986"
[1] "85 ВЮ╝В░е: ЖхгВёюв▓ё: 0.013 ВІаВёюв▓ё: 99.987"
[1] "86 ВЮ╝В░е: ЖхгВёюв▓ё: 0.012 ВІаВёюв▓ё: 99.988"
[1] "87 ВЮ╝В░е: ЖхгВёюв▓ё: 0.01 ВІаВёюв▓ё: 99.99"
[1] "88 ВЮ╝В░е: ЖхгВёюв▓ё: 0.009 ВІаВёюв▓ё: 99.991"
[1] "89 ВЮ╝В░е: ЖхгВёюв▓ё: 0.008 ВІаВёюв▓ё: 99.992"
[1] "90 ВЮ╝В░е: ЖхгВёюв▓ё: 0.008 ВІаВёюв▓ё: 99.992"
[1] "91 ВЮ╝В░е: ЖхгВёюв▓ё: 0.007 ВІаВёюв▓ё: 99.993"
[1] "92 ВЮ╝В░е: ЖхгВёюв▓ё: 0.006 ВІаВёюв▓ё: 99.994"
[1] "93 ВЮ╝В░е: ЖхгВёюв▓ё: 0.006 ВІаВёюв▓ё: 99.994"
[1] "94 ВЮ╝В░е: ЖхгВёюв▓ё: 0.005 ВІаВёюв▓ё: 99.995"
[1] "95 ВЮ╝В░е: ЖхгВёюв▓ё: 0.004 ВІаВёюв▓ё: 99.996"
[1] "96 ВЮ╝В░е: ЖхгВёюв▓ё: 0.004 ВІаВёюв▓ё: 99.996"
[1] "97 ВЮ╝В░е: ЖхгВёюв▓ё: 0.004 ВІаВёюв▓ё: 99.996"
[1] "98 ВЮ╝В░е: ЖхгВёюв▓ё: 0.003 ВІаВёюв▓ё: 99.997"
[1] "99 ВЮ╝В░е: ЖхгВёюв▓ё: 0.003 ВІаВёюв▓ё: 99.997"
[1] "100 ВЮ╝В░е: ЖхгВёюв▓ё: 0.003 ВІаВёюв▓ё: 99.997"
[1] "101 ВЮ╝В░е: ЖхгВёюв▓ё: 0.002 ВІаВёюв▓ё: 99.998"
[1] "102 ВЮ╝В░е: ЖхгВёюв▓ё: 0.002 ВІаВёюв▓ё: 99.998"
[1] "103 ВЮ╝В░е: ЖхгВёюв▓ё: 0.002 ВІаВёюв▓ё: 99.998"
[1] "104 ВЮ╝В░е: ЖхгВёюв▓ё: 0.002 ВІаВёюв▓ё: 99.998"
[1] "105 ВЮ╝В░е: ЖхгВёюв▓ё: 0.002 ВІаВёюв▓ё: 99.998"
[1] "106 ВЮ╝В░е: ЖхгВёюв▓ё: 0.001 ВІаВёюв▓ё: 99.999"
[1] "107 ВЮ╝В░е: ЖхгВёюв▓ё: 0.001 ВІаВёюв▓ё: 99.999"
[1] "108 ВЮ╝В░е: ЖхгВёюв▓ё: 0.001 ВІаВёюв▓ё: 99.999"
[1] "109 ВЮ╝В░е: ЖхгВёюв▓ё: 0.001 ВІаВёюв▓ё: 99.999"
[1] "110 ВЮ╝В░е: ЖхгВёюв▓ё: 0.001 ВІаВёюв▓ё: 99.999"
[1] "111 ВЮ╝В░е: ЖхгВёюв▓ё: 0.001 ВІаВёюв▓ё: 99.999"
[1] "112 ВЮ╝В░е: ЖхгВёюв▓ё: 0.001 ВІаВёюв▓ё: 99.999"
[1] "113 ВЮ╝В░е: ЖхгВёюв▓ё: 0.001 ВІаВёюв▓ё: 99.999"
[1] "114 ВЮ╝В░е: ЖхгВёюв▓ё: 0.001 ВІаВёюв▓ё: 99.999"
[1] "115 ВЮ╝В░е: ЖхгВёюв▓ё: 0.001 ВІаВёюв▓ё: 99.999"
[1] "116 ВЮ╝В░е: ЖхгВёюв▓ё: 0 ВІаВёюв▓ё: 100"
[1] "117 ВЮ╝В░е: ЖхгВёюв▓ё: 0 ВІаВёюв▓ё: 100"
[1] "118 ВЮ╝В░е: ЖхгВёюв▓ё: 0 ВІаВёюв▓ё: 100"
[1] "119 ВЮ╝В░е: ЖхгВёюв▓ё: 0 ВІаВёюв▓ё: 100"
[1] "120 ВЮ╝В░е: ЖхгВёюв▓ё: 0 ВІаВёюв▓ё: 100"
[edit]
6 ВўѕВаю3: ВбЁьЋЕв│ЉВЏљ ВІгВъЦ В╣ўвБї в│ЉвЈЎ #
ВўѕВаюВХюВ▓ў: http://secom.hanbat.ac.kr/or/chapter1/right04.html
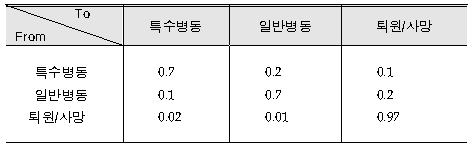
| Вќ┤віљ ВбЁьЋЕв│ЉВЏљВЮў ВІгВъЦв│Љ В╣ўвБї ьі╣Вѕўв│ЉвЈЎВЌљ ВъЁВЏљВцЉВЮИ ьЎўВъљвіћ ьЎўВъљВЮў ВЃЂьЃюВЌљ вћ░вЮ╝ ВЮ╝в░ўв│ЉвЈЎВю╝вАю ВЮ┤вЈЎьЋўЖ▒░вѓў ьЄ┤ВЏљьЋўвіћвЇ░, ьЄ┤ВЏљьЋўвіћ Ж▓йВџ░ ВцЉ 85%віћ В╣ўвБївљўВќ┤ ьЄ┤ВЏљьЋўвЕ░ 15%віћ ВѓгвДЮьЋўвіћ Ж▓йВџ░ВЮ┤вІц. В╣ўвБївљўВќ┤ ьЄ┤ВЏљьЋю ьЎўВъљВцЉ ВЮ╝вХђвіћ ВЃѕвАюВџ┤ ьЎўВъљвАюВёю вІцВІю ВъЁВЏљьЋўЖИ░вЈё ьЋўвЕ░ В╣ўвБївїђВЃЂВЮИ ВІгВъЦв│ЉьЎўВъљВЮў ВѕўЖ░ђ ВЮ╝ВаЋьЋўЖ│а, 1ВЮ╝ ВаёВЮ┤ьЎЋвЦаВЮ┤ ВЋёвъўВЮў ьЉюВЎђ Ж░ЎвІцЖ│а ьЋювІц. |
x1 <- c(0.7, 0.2, 0.1)
x2 <- c(0.1, 0.7, 0.2)
x3 <- c(0.02, 0.01, 0.97)
tp <- rbind(x1, x2, x3) #ВаёВЮ┤ьЎЋвЦа
ss <- rbind(c(1,0,0)) #ВІюВ┤ѕ
for(t in seq(1:50)){
prev_tp <- ss%*%tp
out <- paste(t, "ВЮ╝В░е: ",
"ьі╣Вѕўв│ЉвЈЎ:", round(prev_tp[1,1], 3),
"ВЮ╝в░ўв│ЉвЈЎ:", round(prev_tp[1,2], 3),
"ьЄ┤ВЏљ/ВѓгвДЮ:", round(prev_tp[1,3], 3)
)
ss <- prev_tp
print (out)
}
Ж▓░Ж│╝
[1] "1 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.7 ВЮ╝в░ўв│ЉвЈЎ: 0.2 ьЄ┤ВЏљ/ВѓгвДЮ: 0.1" [1] "2 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.512 ВЮ╝в░ўв│ЉвЈЎ: 0.281 ьЄ┤ВЏљ/ВѓгвДЮ: 0.207" [1] "3 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.391 ВЮ╝в░ўв│ЉвЈЎ: 0.301 ьЄ┤ВЏљ/ВѓгвДЮ: 0.308" [1] "4 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.31 ВЮ╝в░ўв│ЉвЈЎ: 0.292 ьЄ┤ВЏљ/ВѓгвДЮ: 0.398" [1] "5 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.254 ВЮ╝в░ўв│ЉвЈЎ: 0.27 ьЄ┤ВЏљ/ВѓгвДЮ: 0.476" [1] "6 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.214 ВЮ╝в░ўв│ЉвЈЎ: 0.245 ьЄ┤ВЏљ/ВѓгвДЮ: 0.541" [1] "7 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.185 ВЮ╝в░ўв│ЉвЈЎ: 0.22 ьЄ┤ВЏљ/ВѓгвДЮ: 0.595" [1] "8 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.164 ВЮ╝в░ўв│ЉвЈЎ: 0.197 ьЄ┤ВЏљ/ВѓгвДЮ: 0.64" [1] "9 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.147 ВЮ╝в░ўв│ЉвЈЎ: 0.177 ьЄ┤ВЏљ/ВѓгвДЮ: 0.676" [1] "10 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.134 ВЮ╝в░ўв│ЉвЈЎ: 0.16 ьЄ┤ВЏљ/ВѓгвДЮ: 0.706" [1] "11 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.124 ВЮ╝в░ўв│ЉвЈЎ: 0.146 ьЄ┤ВЏљ/ВѓгвДЮ: 0.73" [1] "12 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.116 ВЮ╝в░ўв│ЉвЈЎ: 0.134 ьЄ┤ВЏљ/ВѓгвДЮ: 0.75" [1] "13 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.11 ВЮ╝в░ўв│ЉвЈЎ: 0.125 ьЄ┤ВЏљ/ВѓгвДЮ: 0.766" [1] "14 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.104 ВЮ╝в░ўв│ЉвЈЎ: 0.117 ьЄ┤ВЏљ/ВѓгвДЮ: 0.779" [1] "15 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.1 ВЮ╝в░ўв│ЉвЈЎ: 0.11 ьЄ┤ВЏљ/ВѓгвДЮ: 0.789" [1] "16 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.097 ВЮ╝в░ўв│ЉвЈЎ: 0.105 ьЄ┤ВЏљ/ВѓгвДЮ: 0.798" [1] "17 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.094 ВЮ╝в░ўв│ЉвЈЎ: 0.101 ьЄ┤ВЏљ/ВѓгвДЮ: 0.804" [1] "18 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.092 ВЮ╝в░ўв│ЉвЈЎ: 0.098 ьЄ┤ВЏљ/ВѓгвДЮ: 0.81" [1] "19 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.091 ВЮ╝в░ўв│ЉвЈЎ: 0.095 ьЄ┤ВЏљ/ВѓгвДЮ: 0.814" [1] "20 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.089 ВЮ╝в░ўв│ЉвЈЎ: 0.093 ьЄ┤ВЏљ/ВѓгвДЮ: 0.818" [1] "21 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.088 ВЮ╝в░ўв│ЉвЈЎ: 0.091 ьЄ┤ВЏљ/ВѓгвДЮ: 0.821" [1] "22 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.087 ВЮ╝в░ўв│ЉвЈЎ: 0.089 ьЄ┤ВЏљ/ВѓгвДЮ: 0.823" [1] "23 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.086 ВЮ╝в░ўв│ЉвЈЎ: 0.088 ьЄ┤ВЏљ/ВѓгвДЮ: 0.825" [1] "24 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.086 ВЮ╝в░ўв│ЉвЈЎ: 0.087 ьЄ┤ВЏљ/ВѓгвДЮ: 0.827" [1] "25 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.085 ВЮ╝в░ўв│ЉвЈЎ: 0.087 ьЄ┤ВЏљ/ВѓгвДЮ: 0.828" [1] "26 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.085 ВЮ╝в░ўв│ЉвЈЎ: 0.086 ьЄ┤ВЏљ/ВѓгвДЮ: 0.829" [1] "27 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.085 ВЮ╝в░ўв│ЉвЈЎ: 0.085 ьЄ┤ВЏљ/ВѓгвДЮ: 0.83" [1] "28 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.084 ВЮ╝в░ўв│ЉвЈЎ: 0.085 ьЄ┤ВЏљ/ВѓгвДЮ: 0.831" [1] "29 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.084 ВЮ╝в░ўв│ЉвЈЎ: 0.085 ьЄ┤ВЏљ/ВѓгвДЮ: 0.831" [1] "30 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.084 ВЮ╝в░ўв│ЉвЈЎ: 0.084 ьЄ┤ВЏљ/ВѓгвДЮ: 0.832" [1] "31 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.084 ВЮ╝в░ўв│ЉвЈЎ: 0.084 ьЄ┤ВЏљ/ВѓгвДЮ: 0.832" [1] "32 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.084 ВЮ╝в░ўв│ЉвЈЎ: 0.084 ьЄ┤ВЏљ/ВѓгвДЮ: 0.832" [1] "33 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.084 ВЮ╝в░ўв│ЉвЈЎ: 0.084 ьЄ┤ВЏљ/ВѓгвДЮ: 0.832" [1] "34 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.084 ВЮ╝в░ўв│ЉвЈЎ: 0.084 ьЄ┤ВЏљ/ВѓгвДЮ: 0.833" [1] "35 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.084 ВЮ╝в░ўв│ЉвЈЎ: 0.084 ьЄ┤ВЏљ/ВѓгвДЮ: 0.833" [1] "36 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.084 ВЮ╝в░ўв│ЉвЈЎ: 0.084 ьЄ┤ВЏљ/ВѓгвДЮ: 0.833" [1] "37 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.083 ВЮ╝в░ўв│ЉвЈЎ: 0.084 ьЄ┤ВЏљ/ВѓгвДЮ: 0.833" [1] "38 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.083 ВЮ╝в░ўв│ЉвЈЎ: 0.084 ьЄ┤ВЏљ/ВѓгвДЮ: 0.833" [1] "39 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.083 ВЮ╝в░ўв│ЉвЈЎ: 0.083 ьЄ┤ВЏљ/ВѓгвДЮ: 0.833" [1] "40 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.083 ВЮ╝в░ўв│ЉвЈЎ: 0.083 ьЄ┤ВЏљ/ВѓгвДЮ: 0.833" [1] "41 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.083 ВЮ╝в░ўв│ЉвЈЎ: 0.083 ьЄ┤ВЏљ/ВѓгвДЮ: 0.833" [1] "42 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.083 ВЮ╝в░ўв│ЉвЈЎ: 0.083 ьЄ┤ВЏљ/ВѓгвДЮ: 0.833" [1] "43 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.083 ВЮ╝в░ўв│ЉвЈЎ: 0.083 ьЄ┤ВЏљ/ВѓгвДЮ: 0.833" [1] "44 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.083 ВЮ╝в░ўв│ЉвЈЎ: 0.083 ьЄ┤ВЏљ/ВѓгвДЮ: 0.833" [1] "45 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.083 ВЮ╝в░ўв│ЉвЈЎ: 0.083 ьЄ┤ВЏљ/ВѓгвДЮ: 0.833" [1] "46 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.083 ВЮ╝в░ўв│ЉвЈЎ: 0.083 ьЄ┤ВЏљ/ВѓгвДЮ: 0.833" [1] "47 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.083 ВЮ╝в░ўв│ЉвЈЎ: 0.083 ьЄ┤ВЏљ/ВѓгвДЮ: 0.833" [1] "48 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.083 ВЮ╝в░ўв│ЉвЈЎ: 0.083 ьЄ┤ВЏљ/ВѓгвДЮ: 0.833" [1] "49 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.083 ВЮ╝в░ўв│ЉвЈЎ: 0.083 ьЄ┤ВЏљ/ВѓгвДЮ: 0.833" [1] "50 ВЮ╝В░е: ьі╣Вѕўв│ЉвЈЎ: 0.083 ВЮ╝в░ўв│ЉвЈЎ: 0.083 ьЄ┤ВЏљ/ВѓгвДЮ: 0.833"ВІгВъЦв│ЉьЎўВъљВЮў 8.3%ВћЕВЮ┤ Ж░ЂЖ░Ђ ьі╣Вѕўв│ЉвЈЎЖ│╝ ВЮ╝в░ўв│ЉвЈЎВЌљВёю В╣ўвБїВцЉВЮ┤вЕ░ 83.34%віћ ВѓгвДЮьЋўВўђЖ▒░вѓў В╣ўвБївљўВќ┤ ьЄ┤ВЏљьЋю ВЃЂьЃювЮ╝Ж│а ВХћВаЋьЋа Вѕў ВъѕвІц.
[edit]
7 ВўѕВаю4: ВбЁьЋЕв│ЉВЏљ ВІгВъЦ В╣ўвБї в│ЉвЈЎ - markovchain packages #
http://cran.r-project.org/web/packages/markovchain/markovchain.pdf
install.packages("markovchain")
library("markovchain")
statesNames=c("ьі╣Вѕўв│ЉвЈЎ","ВЮ╝в░ўв│ЉвЈЎ", "ьЄ┤ВЏљ/ВѓгвДЮ")
mt <- matrix(c(0.7,0.2,0.1,0.1,0.7,0.2,0.02,0.01,0.97), byrow=TRUE, nrow=3)
mc<-new("markovchain", transitionMatrix=mt, states=statesNames)
mc^2 #2в▓ѕВДИ вІеЖ│ё
steadyStates(mc)
Ж▓░Ж│╝
> mc^2
A Markov chain^2
A 3 - dimensional discrete Markov Chain with following states
ьі╣Вѕўв│ЉвЈЎ ВЮ╝в░ўв│ЉвЈЎ ьЄ┤ВЏљ/ВѓгвДЮ
The transition matrix (by rows) is defined as follows
ьі╣Вѕўв│ЉвЈЎ ВЮ╝в░ўв│ЉвЈЎ ьЄ┤ВЏљ/ВѓгвДЮ
ьі╣Вѕўв│ЉвЈЎ 0.5120 0.2810 0.2070
ВЮ╝в░ўв│ЉвЈЎ 0.1440 0.5120 0.3440
ьЄ┤ВЏљ/ВѓгвДЮ 0.0344 0.0207 0.9449
> steadyStates(mcA)
ьі╣Вѕўв│ЉвЈЎ ВЮ╝в░ўв│ЉвЈЎ ьЄ┤ВЏљ/ВѓгвДЮ
[1,] 0.08333333 0.08333333 0.8333333
[edit]
8 ВўѕВаю5: вЇ░ВЮ┤ьё░ ьћёваѕВъёВЮё ВаёВЮ┤ ьЎЋвЦавАю вДївЊцЖИ░ #
raw <- data.frame(name=c("f1","f1","f1","f1","f2","f2","f2","f2"),
year=c(83, 84, 85, 86, 83, 84, 85, 86),
state=sample(1:3, 8, replace=TRUE)
)
transition.probabilities <- function(D, timevar="year",
idvar="name", statevar="state") {
merged <- merge(D, cbind(nextt=D[,timevar] + 1, D),
by.x = c(timevar, idvar), by.y = c("nextt", idvar))
t(table(merged[, grep(statevar, names(merged), value = TRUE)]))
}
transition.probabilities(raw, timevar="year", idvar="name",statevar="state")
install.packages("markovchain")
library("markovchain")
sequence<-c("a", "b", "a", "a", "a", "a", "b", "a", "b", "a", "b", "a", "a", "b", "b", "b", "a")
mcFitMLE<-markovchainFit(data=sequence)
#str(mcFitMLE)
#mcFitMLE$estimate@transitionMatrix
#mcFitMLE$estimate@states
markov<-new("markovchain", states=mcFitMLE$estimate@states, transitionMatrix=mcFitMLE$estimate@transitionMatrix)
plotMc(markov)
[edit]
9 ВўѕВаю6: ьЮАВѕўВЃЂьЃюЖ░ђ ьЈгьЋевљю ВаёВЮ┤ьќЅваг #
Dв░▒ьЎћВаљ 1,000Ж│аЖ░ЮВЮў ВІаВџЕЖ│ёВаЋ ВЃЂьЃю(http://secom.hanbat.ac.kr/or/chapter1/right04.html)
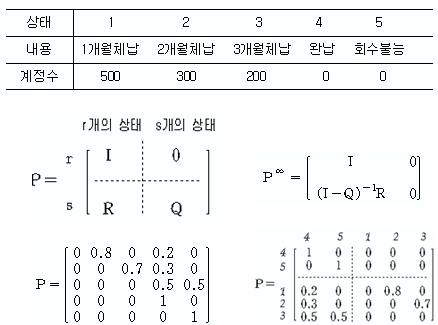
R <- matrix(c(0.2,0, 0.3,0,0.5,0.5), byrow=TRUE, nrow=3) Q <- matrix(c(0,0.8,0,0,0,0.7,0,0,0), byrow=TRUE, nrow=3) IQ <- diag(rep(1,3)) - Q IQ iIQ<-ginv(IQ) iIQ %*% R rowSums(iIQ)
[edit]
10 HMM(Hidden Markov Model) #
- вДѕВйћьћё вфевЇИВЌљ 'ВЮђвІЅ'ВЮ┤вЮ╝віћ Ж░ювЁљВЮё ВХћЖ░ђ
- ВіцВ╣╝вЮ╝ & ВЮ┤Вѓ░ ВЮ┤Вќ┤ВЋ╝ ьЋе.
вѓаВћеВЮў ВаёВЮ┤ ьќЅвагВЮ┤ вІцВЮїЖ│╝ Ж░ЎвІц.
| в╣ё | ьЋ┤ | |
| в╣ё | 0.7 | 0.3 |
| ьЋ┤ | 0.4 | 0.6 |
В┤ѕЖИ░ ВЃЂьЃю ьЎЋвЦаВЮђ
- в╣ё = 0.6
- ьЋ┤ = 0.4
- в╣ё
- Вѓ░В▒Ё = 0.1
- ВЄ╝ьЋЉ = 0.4
- В▓ГВєї = 0.5
- Вѓ░В▒Ё = 0.1
- ьЋ┤
- Вѓ░В▒Ё = 0.6
- ВЄ╝ьЋЉ = 0.3
- В▓ГВєї = 0.1
- Вѓ░В▒Ё = 0.6
#install.packages("RHmm")
library("RHmm")
weatherTransitions <-
rbind(
c(0.7, 0.3),
c(0.4, 0.6)
)
s1 <- c(0.1, 0.4, 0.5)
s2 <- c(0.6, 0.3, 0.1)
dist <- distributionSet(dis="DISCRETE", proba=list(s1, s2), labels =c("Вѓ░В▒Ё", "ВЄ╝ьЋЉ", "В▓ГВєї"))
dist
weatherHmm <- HMMSet(initProb=c(0.6, 0.4), transMat=weatherTransitions, distribution=dist)
weatherPath <- viterbi(HMM=weatherHmm, obs=c("Вѓ░В▒Ё", "Вѓ░В▒Ё", "В▓ГВєї", "ВЄ╝ьЋЉ"))
weatherPath
Ж▓░Ж│╝
> weatherPath $states [1] 2 2 1 1 $logViterbiScore [1] -5.331171 $logProbSeq [1] -0.8306799 attr(,"class") [1] "viterbiClass" >
- statesЖ░ђ 2 2 1 1вАю 'ьЋ┤->ьЋ┤->в╣ё->в╣ё' ВўђВЮё Ж░ђвіЦВё▒ВЮ┤ ВаюВЮ╝ ьЂгвІц.
- 'Вѓ░В▒Ё->Вѓ░В▒Ё->В▓ГВєї->ВЄ╝ьЋЉ'ВЮў ВхюВаЂ ВЃЂьЃюВЌ┤ВЮў Ж░њ(viterbi score)ВЮђ 0.0048384вІц. (exp(weatherPath$logViterbiScore))
- 'Вѓ░В▒Ё->Вѓ░В▒Ё->В▓ГВєї->ВЄ╝ьЋЉ'ВЮў в░юВЃЮ ьЎЋвЦаВЮђ 0.4357529 (exp(weatherPath$logProbSeq)) --> вДъвѓў??
- ЖиИвЁђЖ░ђ ВЮ╝ВБ╝ВЮ╝ ВЌ░ВєЇВю╝вАю ВЄ╝ьЋЉвДї ьЋа ьЎЋвЦаВЮђ?
- 'Вѓ░В▒Ё->Вѓ░В▒Ё->В▓ГВєї'вЦ╝ ьЋю Ж▓йВџ░ 3ВЮ╝Ж░ёВЮў вѓаВћевіћ?
- ВДђвѓю 3ВЮ╝ вЈЎВЋѕ 'Вѓ░В▒Ё->Вѓ░В▒Ё->В▓ГВєї'вЦ╝ ьќѕвіћвЇ░, ВўцвіўЖ│╝ вѓ┤ВЮ╝ВЮђ вг┤ВЌЄВЮё ьЋа Ж▓ЃВю╝вАю ВўѕВИАвљўвѓў?
[edit]
11 msm package #
library("msm")
data("cav")
str(cav)
cav <- cav[!is.na(cav$pdiag),]
cav[1:11,]
m <- statetable.msm(state, PTNUM, data = cav)
class(m)
twoway4.q <- rbind(c(0, 0.25, 0, 0.25),
c(0.166, 0, 0.166, 0.166),
c(0, 0.25, 0, 0.25),
c(0, 0, 0, 0))
rownames(twoway4.q) <- colnames(twoway4.q) <- c("Well", "Mild", "Severe", "Death")
cav.msm <- msm(state ~ years, subject = PTNUM, data = cav, qmatrix = twoway4.q, death = 4)
#pmatrix.msm(cav.msm, t = 1, ci = "normal")
pmatrix.msm(cav.msm, t = 1, ci = "none")
> pmatrix.msm(cav.msm, t = 1, ci = "none")
Well Mild Severe Death
Well 0.853040629 0.08916579 0.01486643 0.04292715
Mild 0.156269251 0.56585635 0.20550354 0.07237086
Severe 0.009996569 0.07884756 0.66057662 0.25057925
Death 0.000000000 0.00000000 0.00000000 1.00000000
[edit]
12 ВаЋвДљ ВЮ┤вЪ░ в│хВъАьЋюЖ▓ї ьЋёВџћьЋюЖ░ђ? #
Ж│аЖ░ЮВЮ┤ 100вДї вфЁВЮ┤ ВъѕвІц. Ж│аЖ░ЮвЊцВЮё Ж░ђВъЁ,ЖхгвДц,ВЮ┤ьЃѕВЌљ вїђьЋ┤ ВХћВаЂьЋ┤ в┤цВю╝вЕ░, вІцВЮїЖ│╝ Ж░ЎВЮђ ьїеьё┤ВЮё в│┤ВўђвІц.
| ьїеьё┤ | в╣ёВюе |
| Ж░ђВъЁ | 50% |
| Ж░ђВъЁ->ВЮ┤ьЃѕ | 30% |
| Ж░ђВъЁ->ЖхгвДц->ЖхгвДц->ВЮ┤ьЃѕ | 10% |
| Ж░ђВъЁ->ЖхгвДц | 5% |
| Ж░ђВъЁ->ЖхгвДц->ВЮ┤ьЃѕ | 3% |
| Ж░ђВъЁ->ЖхгвДц->ЖхгвДц->ЖхгвДц | 2% |
'Ж░ђВъЁ->ЖхгвДц->?' вг╝ВЮїьЉю(?)віћ вг┤ВЌЄВЮ┤Ж▓авіћЖ░ђ? вІ╣ВЌ░ьъѕ 'ЖхгвДц'ВЮ╝ ьЎЋвЦаВЮ┤ вєњВДђ ВЋіЖ▓авіћЖ░ђ?
ВЮї..вЇ░ВЮ┤ьё░ вХёВёЮВЌљВёювіћ вДѕВйћьћё вфевЇИВЮ┤ ьЋёВџћьЋўВДђ ВЋіВЮё ВѕўвЈё ВъѕЖ▓авІц.
[edit]
13 В░ИЖ│аВъљвБї #
![[https]](/moniwiki/imgs/https.png) Attribution model with R (part 1: Markov chains concept)
Attribution model with R (part 1: Markov chains concept)
- Getting Started with Markov Chains
- http://www.jstatsoft.org/v38/i08/paper --> ВЮ┤Ж▒░ ВбІЖхгвДї..
- https://stat.ethz.ch/pipermail/r-help/2004-May/050424.html
- http://www.r-bloggers.com/basics-on-markov-chain-for-parents-2/
- http://secom.hanbat.ac.kr/or/chapter1/right04.html
- http://www.stat.washington.edu/vminin/markovjumps/rob_dist_tutorial1.html
- http://www.math.ucla.edu/~pejman/intro2prob/LiveMeeting10.pdf
- http://kgeography.or.kr/publishing/journal/47/01/06.pdf
- http://www.chancesis.com/2011/08/14/run-expectancy-and-markov-chains/
- http://visbic.cse.pusan.ac.kr/~dhlee/wiki/images/f/fe/TR_%EA%B9%80%ED%83%9C%ED%98%95.pdf
- Ж▓йВўЂЖ│╝ьЋЎ / Ж░ЋЖИѕВёЮ, ВъЦВџ░ВёЮ
- Viterbi algorithm
№╗┐